一、什么是搜索算法
算法是作用于具体数据结构之上的,深度优先搜索算法和广度优先搜索算法都是基于“图”这种数据结构的。这是因为,图这种数据结构的表达能力很强,大部分涉及搜索的场景都可以抽象成“图”。
图上的搜索算法,最直接的理解就是,在图中找出从一个顶点出发,到另一个顶点的路径。具体方法有很多,比如今天要讲的两种最简单、最“暴力”的深度优先、广度优先搜索,还有 A*、IDA* 等启发式搜索算法。
二、无向图的实现
大佬写的
public class Graph {
// 无向图
private int v; // 顶点的个数
private LinkedList<Integer> adj[]; // 邻接表
public Graph(int v) {
this.v = v;
adj = new LinkedList[v];
for (int i=0; i<v; ++i) {
adj[i] = new LinkedList<>();
}
}
public void addEdge(int s, int t) {
// 无向图一条边存两次
adj[s].add(t);
adj[t].add(s);
}
}
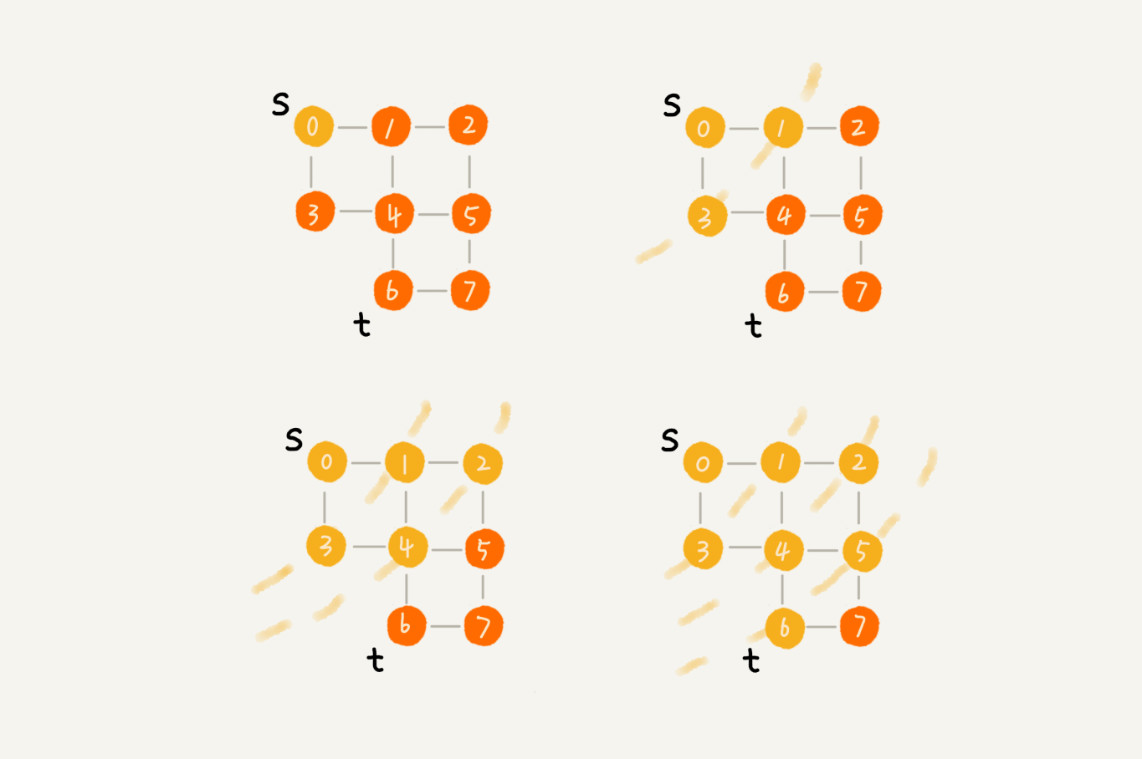
三、广度优先搜索(Breadth-First-Search)
广度优先搜索(Breadth-First-Search),简称 BFS。它其实就是一种“地毯式”层层推进的搜索策略,即先查找离起始顶点最近的,然后是次近的,依次往外搜索。
大佬写的
public void bfs(int s, int t) {
if (s == t) return;
boolean[] visited = new boolean[v];
visited[s]=true;
Queue<Integer> queue = new LinkedList<>();
queue.add(s);
int[] prev = new int[v];
for (int i = 0; i < v; ++i) {
prev[i] = -1;
}
while (queue.size() != 0) {
int w = queue.poll();
for (int i = 0; i < adj[w].size(); ++i) {
int q = adj[w].get(i);
if (!visited[q]) {
prev[q] = w;
if (q == t) {
print(prev, s, t);
return;
}
visited[q] = true;
queue.add(q);
}
}
}
}
private void print(int[] prev, int s, int t) {
// 递归打印s->t的路径
if (prev[t] != -1 && t != s) {
print(prev, s, prev[t]);
}
System.out.print(t + " ");
}
我自己写的
在这里插入代码片
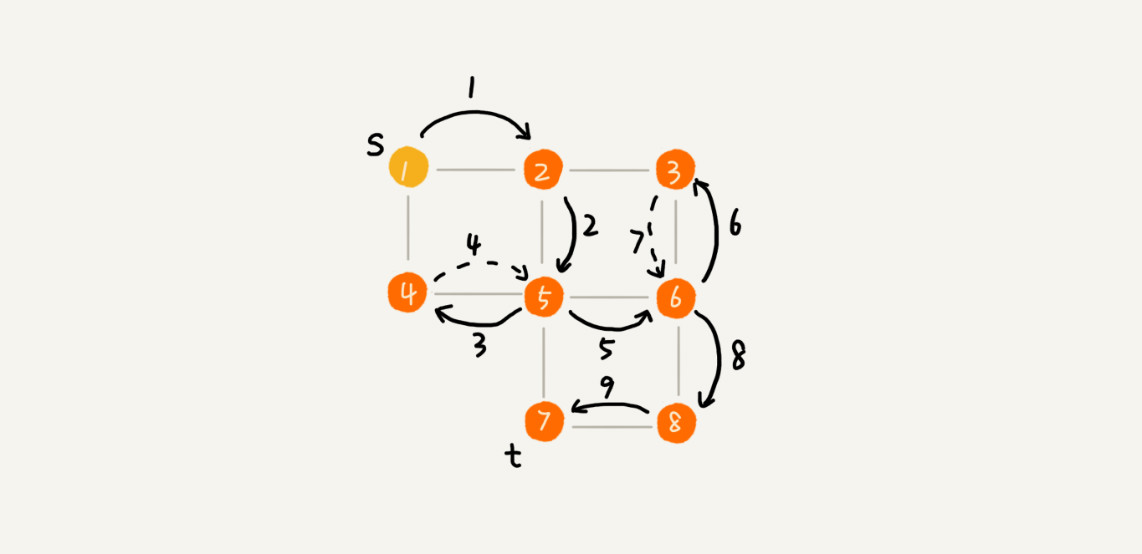
三、深度优先搜索(Depth-First-Search)
深度优先搜索(Depth-First-Search),简称 DFS。最直观的例子就是“走迷宫”。假设你站在迷宫的某个岔路口,然后想找到出口。你随意选择一个岔路口来走,走着走着发现走不通的时候,你就回退到上一个岔路口,重新选择一条路继续走,直到最终找到出口。这种走法就是一种深度优先搜索策略。
大佬写的
boolean found = false; // 全局变量或者类成员变量
public void dfs(int s, int t) {
found = false;
boolean[] visited = new boolean[v];
int[] prev = new int[v];
for (int i = 0; i < v; ++i) {
prev[i] = -1;
}
recurDfs(s, t, visited, prev);
print(prev, s, t);
}
private void recurDfs(int w, int t, boolean[] visited, int[] prev) {
if (found == true) return;
visited[w] = true;
if (w == t) {
found = true;
return;
}
for (int i = 0; i < adj[w].size(); ++i) {
int q = adj[w].get(i);
if (!visited[q]) {
prev[q] = w;
recurDfs(q, t, visited, prev);
}
}
}
我自己写的
版权声明:本文不是「本站」原创文章,版权归原作者所有 | 原文地址: