一、堆(Heap)
堆是一种特殊的树,只要满足这两点,它就是一个堆。
1、 堆是一个完全二叉树;
2、 堆中每一个节点的值都必须大于等于(或小于等于)其子树中每个节点的值;
总结一下是堆的全部子节点>=父节点OR子节点<=父节点,目标节点如果有一个子节点必须是左子节点,子节点左右大小无序。
一.什么是完全二叉树
复习一下
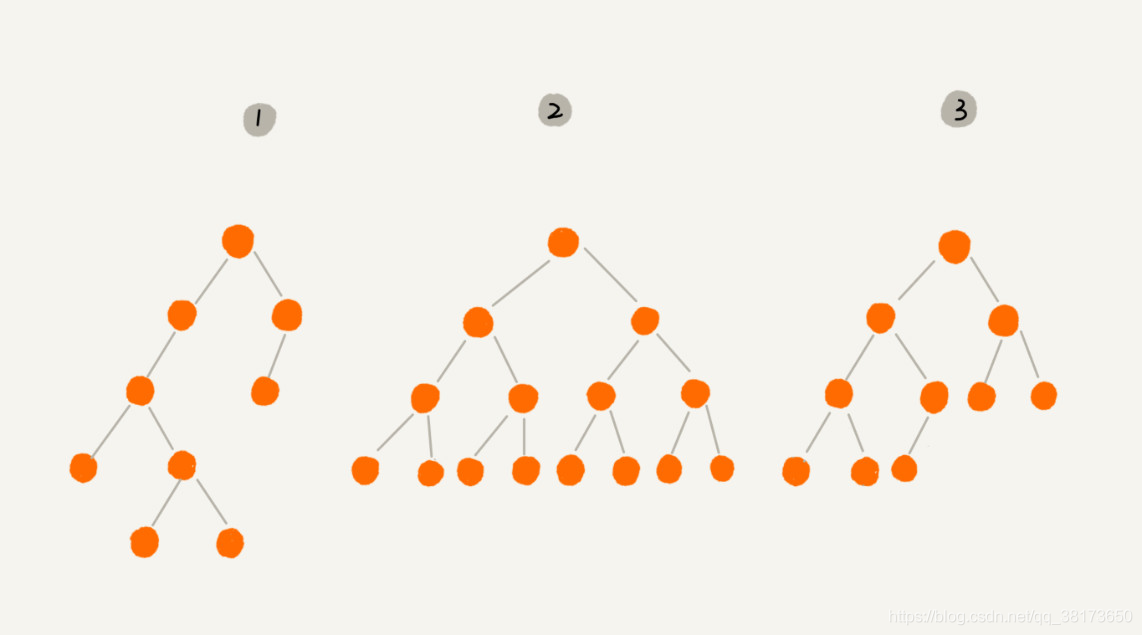
编号2 的二叉树中,叶子节点全都在最底层,除了叶子节点之外,每个节点都有左右两个子节点,这种二叉树就叫做满二叉树。
编号3 的二叉树中,若设二叉树的深度为k,除第 k 层外,其它各层 (1~k-1) 的结点数都达到最大个数,第k 层所有的结点都连续集中在最左边,这种二叉树叫做完全二叉树,如果一棵二叉树是满二叉树, 则它必定是完全二叉树。
二.堆中每一个节点的值都必须大于等于(或小于等于)其子树中每个节点的值
堆中的每个节点的值必须大于等于(或者小于等于)其子树中每个节点的值。还可以换一种思路,堆中每个节点的值都大于等于(或者小于等于)其左右子节点的值。这两种表述是等价的。对于每个节点的值都大于等于子树中每个节点值的堆,叫“大顶堆”。对于每个节点的值都小于等于子树中每个节点值的堆,做“小顶堆”。
堆和之前的二叉树在节点值不同之处在于之前二叉树的左子节点小于目标节点,右子节点大于目标节点。
对于堆来讲,要么所有的目标节点都大于等于左右节点,要么所有目标节点都小于等于左右节点。
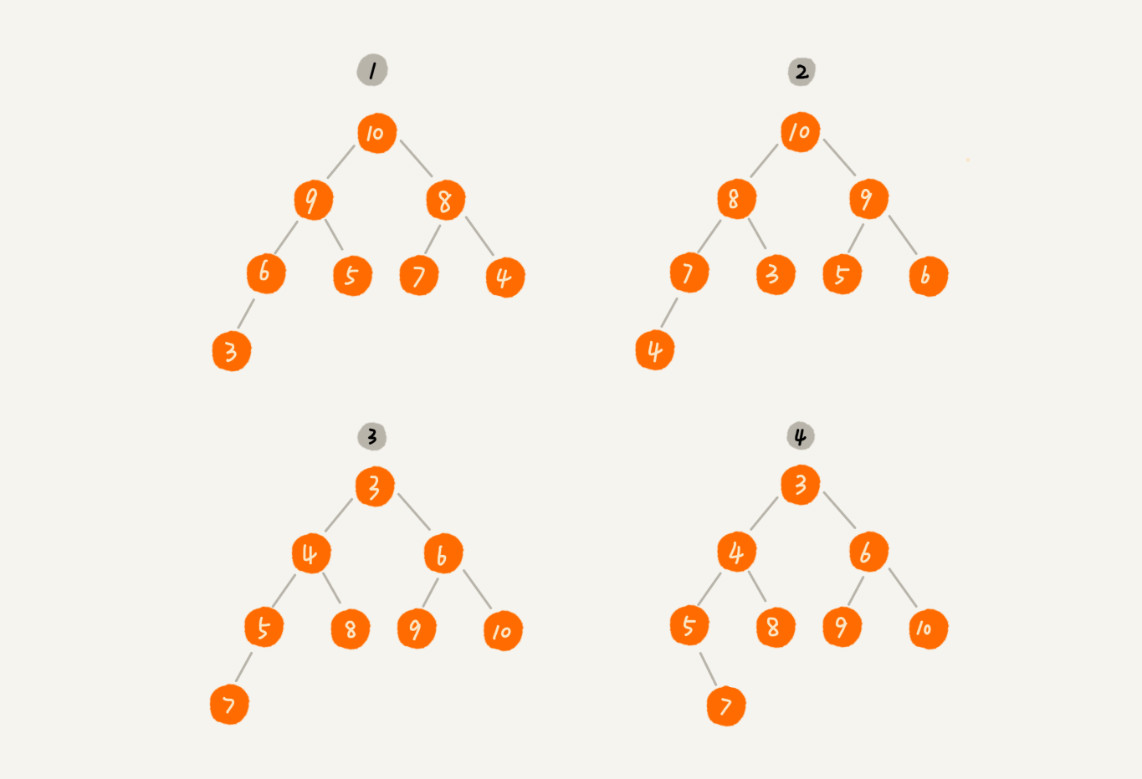
其中第1 个和第 2 个是大顶堆,第 3 个是小顶堆,第 4 个不是堆。
二、如何实现一个堆
一.实现堆
完全二叉树比较适合用数组来存储。用数组来存储完全二叉树是非常节省存储空间的。因为不需要存储左右子节点的指针,单纯地通过数组的下标,就可以找到一个节点的左右子节点和父节点。
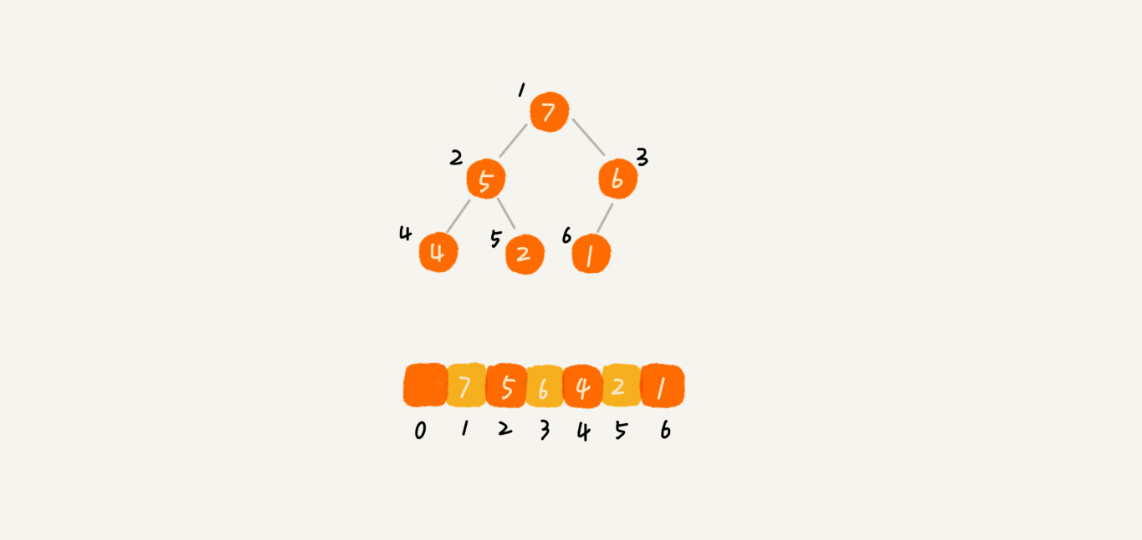
二.堆中插入元素
往堆中插入一个元素后,需要继续满足堆的两个特性。
1、 堆是一个完全二叉树;
2、 堆中每一个节点的值都必须大于等于(或小于等于)其子树中每个节点的值;
往堆中插入元素其实很简单,分为从下往上插入和从上往下插入,我觉得从下往上比较好理解。
如图所示
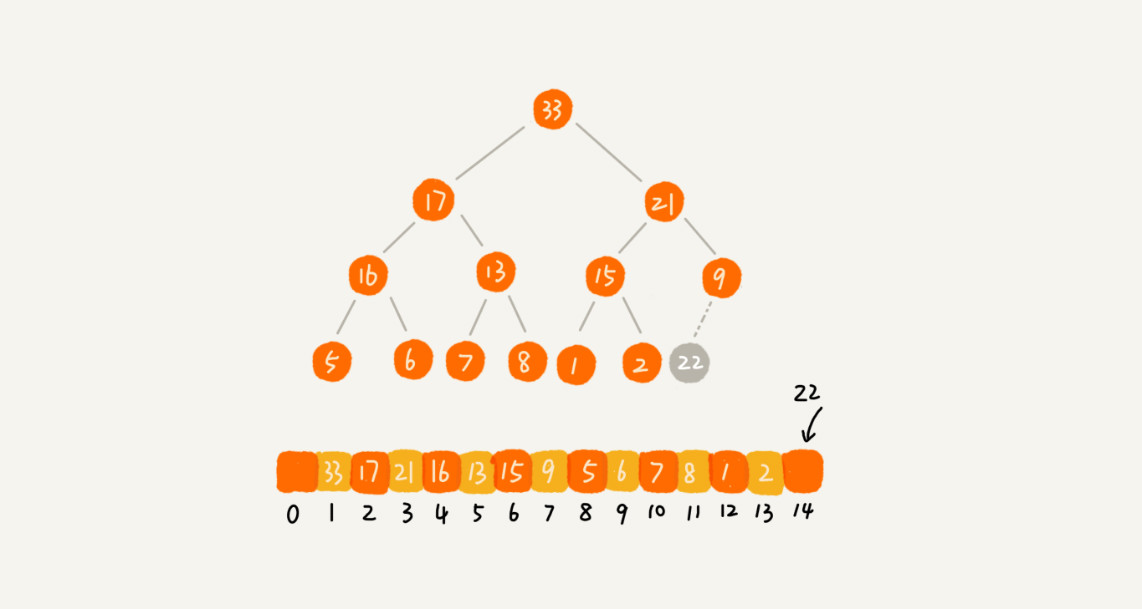
新插入的节点与父节点对比大小。如果不满足子节点小于等于父节点的大小关系,互换两个节点。一直重复这个过程,直到父子节点之间满足刚说的那种大小关系。
一.代码示例
package heap;
public class heapinsertdemo {
static int maxvalue = 20;
static int[] heap = new int[maxvalue + 1];
static int heapcount;//堆中已经存在的个数
public static void main(String[] args) {
int[] insertArray = {
4, 10, 8, 6, 2, 1, 33, 66, 54, 242, 432, 564, 756, 2342, 623, 856, 31, 131, 273, 53, 42};
for (int insertvalue : insertArray) {
heapinsert(insertvalue);
}
printArray("插入后", heap);
}
//插入
public static void heapinsert(int insertvalue) {
if (heapcount >= maxvalue) {
System.out.println("堆满了");
return;
} else {
//1、插入数据,从1位置开始插入数据
heap[heapcount + 1] = insertvalue;
int i = heapcount + 1;
//2、指针挪一位
heapcount++;
//3、判断插入数据和其父节点
while (i / 2 > 0 && heap[i] > heap[i / 2]) {
int a = heap[i / 2];
heap[i / 2] = heap[i];
heap[i] = a;
i = i / 2;
}
}
}
//打印方法
private static void printArray(String pre, int[] MergeArray) {
System.out.print(pre + "\n");
//完成排序后进行输出
for (int element : MergeArray) {
System.out.println(element);
}
}
}
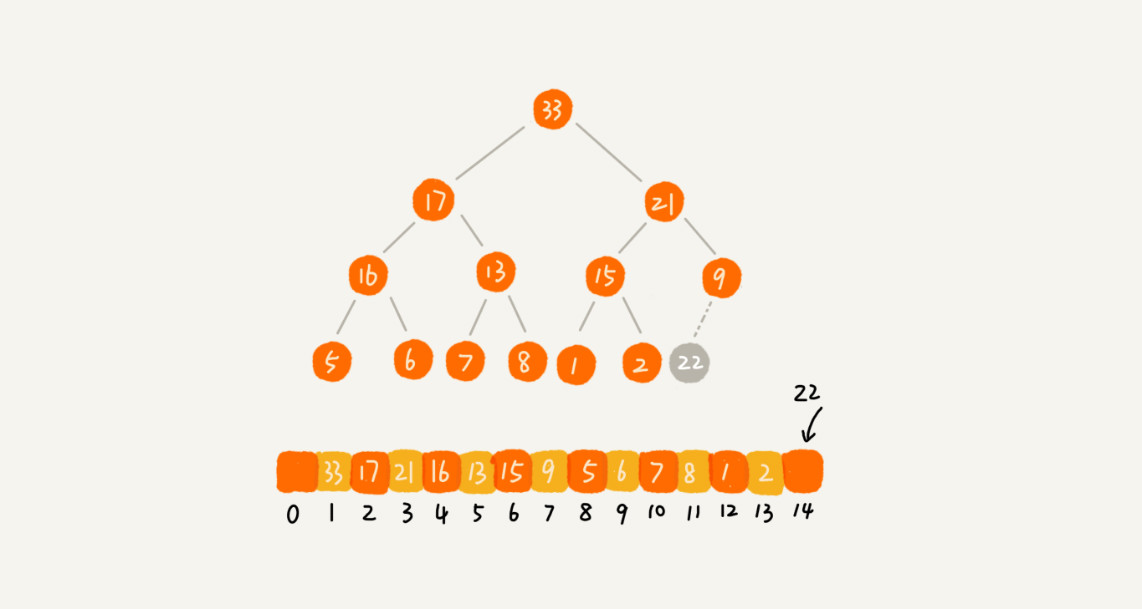
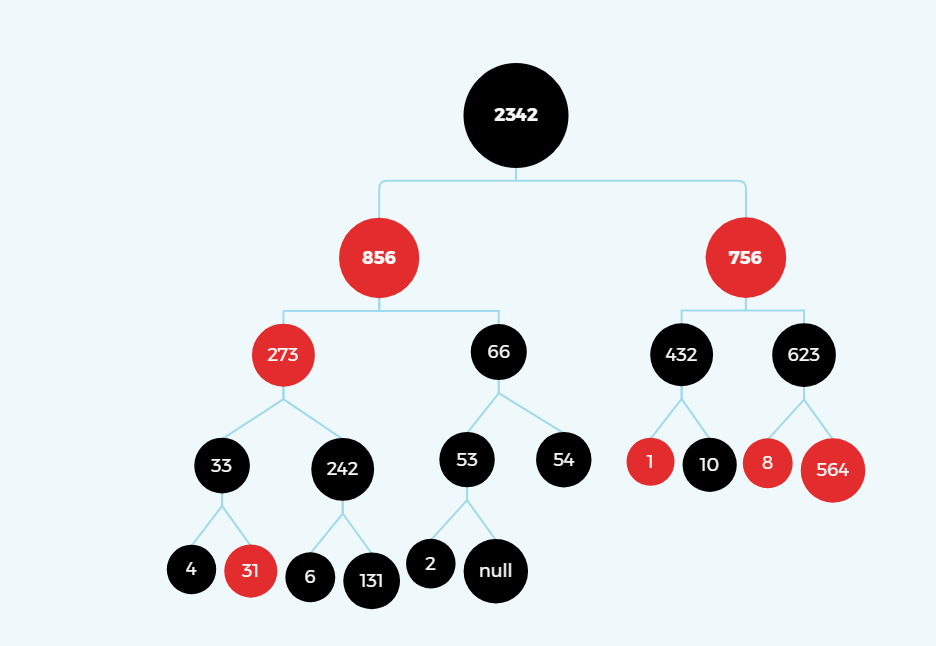
代码执行完毕之后,我自己手动花了一下这个的堆树图,是符合要求的,请忽略颜色。
三.堆中删除元素
从堆的定义的第二条中,任何节点的值都大于等于(或小于等于)子树节点的值,可以发现,堆顶元素存储的就是堆中数据的最大值或者最小值。
假设是大顶堆,堆顶元素就是最大的元素。当删除堆顶元素之后,就需要把第二大的元素放到堆顶,那第二大元素肯定会出现在左右子节点中。然后再迭代地删除第二大节点,以此类推,直到叶子节点被删除。
但是如果只是进行替换的话,存在替换后的数据违背了堆的定义的可能性。
因此可以换一个思路
1、 找出堆中最小的元素节点;
2、 将最小元素与被删除元素节点进行替换(同时和左右两个节点进行比较,和三者中最大的节点进行交换),一直重复这个过程,直到父子节点都满足大小关系为止;
这样因为之发生了交换操作,不会破坏原有平衡性。
这个代码不是我写的。
public void removeMax() {
if (count == 0) return -1; // 堆中没有数据
a[1] = a[count];
--count;
heapify(a, count, 1);
}
private void heapify(int[] a, int n, int i) {
// 自上往下堆化
while (true) {
int maxPos = i;
if (i*2 <= n && a[i] < a[i*2]) maxPos = i*2;
if (i*2+1 <= n && a[maxPos] < a[i*2+1]) maxPos = i*2+1;
if (maxPos == i) break;
swap(a, i, maxPos);
i = maxPos;
}
}
三、堆排序
堆的排序其实可以分为两个步骤,建堆和排序。
一.建堆
完全等同于插入操作
二.排序
堆顶即为最大值,如果删掉堆顶,替换的新的堆顶即为新的最大值,因此排序等同于删除操作。
四、为什么堆排序没有快速排序好
一.堆排序数据访问的方式没有快速排序友好。
对于快速排序来说,数据是顺序访问的。而对于堆排序来说,数据是跳着访问的。 比如,堆排序中,最重要的一个操作就是数据的堆化。比如下面这个例子,对堆顶节点进行堆化,会依次访问数组下标是 1,2,4,8 的元素,而不是像快速排序那样,局部顺序访问,所以,这样对 CPU 缓存是不友好的。
二.对于同样的数据,在排序过程中,堆排序算法的数据交换次数要多于快速排序。
堆排序的第一步是建堆,建堆的过程会打乱数据原有的相对先后顺序,导致原数据的有序度降低。比如,对于一组已经有序的数据来说,经过建堆之后,数据反而变得更无序了。建堆和排序,会有大量的交换操作。
五、堆的应用
一.优先级队列
优先级队列,顾名思义,它首先应该是一个队列。队列最大的特性就是先进先出。不过,在优先级队列中,数据的出队顺序不是先进先出,而是按照优先级来,优先级最高的,最先出队。
堆和优先级队列非常相似。一个堆就可以看作一个优先级队列。很多时候,它们只是概念上的区分而已。往优先级队列中插入一个元素,就相当于往堆中插入一个元素;从优先级队列中取出优先级最高的元素,就相当于取出堆顶元素。
1、合并有序小文件
假设有100 个小文件,每个文件的大小是 100MB,每个文件中存储的都是有序的字符串。我们希望将这些 100 个小文件合并成一个有序的大文件。
整体思路有点像归并排序中的合并函数。我们从这 100 个文件中,各取第一个字符串,放入数组中,然后比较大小,把最小的那个字符串放入合并后的大文件中,并从数组中删除。
假设,这个最小的字符串来自于 13.txt 这个小文件,我们就再从这个小文件取下一个字符串,放到数组中,重新比较大小,并且选择最小的放入合并后的大文件,将它从数组中删除。依次类推,直到所有的文件中的数据都放入到大文件为止。
原文的案例讲的很绕口…
我听了好几遍才听明白啥意思。
我感觉这个例子举得不是很恰当,我自己举个例子。
比如有100个数组,大小无所谓,可以一样也可以不一样,这个并不重要,但是要有序,假设都是从小到大排列的。
创建一个容量为101的临时数组,因为最多需要放进去100个元素,堆的0为空,将放进去的元素进行堆化处理,也就是插入操作,形成一个小顶堆(从小到大排列),并且移除这个堆的顶堆元素(删除操作),假设这个最小元素是从数组20中取得,移除20的第一个元素,并且将第二个元素取出来增加到这个小顶堆当中,再次移除顶堆元素,第二次移除的顶堆元素就是第二小的元素了。
2、高性能定时器
假设我们有一个定时器,定时器中维护了很多定时任务,每个任务都设定了一个要触发执行的时间点。定时器每过一个很小的单位时间(比如 1 秒),就扫描一遍任务,看是否有任务到达设定的执行时间。如果到达了,就拿出来执行。
但是,这样每过 1 秒就扫描一遍任务列表的做法比较低效,主要原因有两点:第一,任务的约定执行时间离当前时间可能还有很久,这样前面很多次扫描其实都是徒劳的;第二,每次都要扫描整个任务列表,如果任务列表很大的话,势必会比较耗时。
用堆来操作,定时器就不需要间隔的轮询,更不需要遍历整个任务表。
二.利用堆求 Top K
TOPK的意思就是取前K位元素,同样是堆顶移除。
三.利用堆求中位数
中位数,顾名思义,就是处在中间位置的那个数。如果数据的个数是奇数,把数据从小到大排列,那第 2n+1 个数据就是中位数(注意:假设数据是从 0 开始编号的);如果数据的个数是偶数的话,那处于中间位置的数据有两个,第 2n 个和第 2n+1 个数据,这个时候,我们可以随意取一个作为中位数,比如取两个数中靠前的那个,就是第 2n 个数据。
中位数
奇位数:N/2+1
偶位数:N/2和N/2+1
对于一组静态数据,中位数是固定的,先排序,第 N/2 个数据就是中位数。
对于动态数组,如果每次查找中位数,都要先进行排序,那么效率会很低。
操作思路,将一组数据排序之后,分成成两个堆,大顶堆和小顶堆。
大顶堆中存储前半部分数据,小顶堆中存储后半部分数据,且小顶堆中的数据都大于大顶堆中的数据。
如果是偶数,则均分各存N/2
如果是奇数则大顶堆存N/2+1,小顶堆存N/2
如果新加入的数据小于等于大顶堆的堆顶元素,我们就将这个新数据插入到大顶堆;否则,我们就将这个新数据插入到小顶堆。
因为堆顶也是动态更新的,所以
那么小顶对的堆顶和大顶堆的堆顶分别都是中位数。
版权声明:本文不是「本站」原创文章,版权归原作者所有 | 原文地址: