一、如何选择合适的排序算法
如果对小规模数据进行排序,可以选择时间复杂度是 O(n2) 的算法;如果对大规模数据进行排序,时间复杂度是 O(nlogn) 的算法更加高效。所以,为了兼顾任意规模数据的排序,一般都会首选时间复杂度是 O(nlogn) 的排序算法来实现排序函数。
实际上使用归并排序的情况其实并不多。快排在最坏情况下的时间复杂度是 O(n2),而归并排序可以做到平均情况、最坏情况下的时间复杂度都是 O(nlogn),但是归并排序并不是原地排序算法,空间复杂度是 O(n)。所以,粗略点、夸张点讲,如果要排序 100MB 的数据,除了数据本身占用的内存之外,排序算法还要额外再占用 100MB 的内存空间,空间耗费就翻倍了。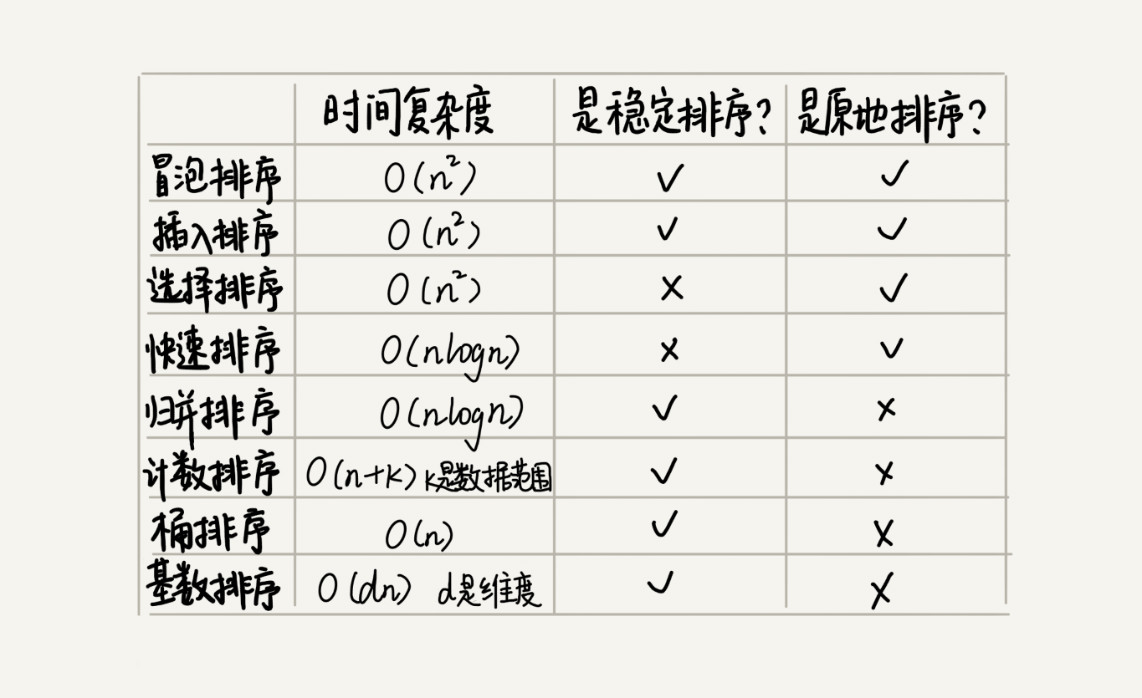
二、如何优化快速排序?
优化快速排序的方法就是选择合适的分区点,尽量的避免变为最坏情况。
一.三数取中法
从区间的首、尾、中间,分别取出一个数,然后对比大小,取这 3 个数的中间值作为分区点。这样每间隔某个固定的长度,取数据出来比较,将中间值作为分区点的分区算法,肯定要比单纯取某一个数据更好。但是,如果要排序的数组比较大,那“三数取中”可能就不够了,可能要“五数取中”或者“十数取中”。
二.随机法
随机法就是每次从要排序的区间中,随机选择一个元素作为分区点。这种方法并不能保证每次分区点都选的比较好,但是从概率的角度来看,也不大可能会出现每次分区点都选得很差的情况,所以平均情况下,这样选的分区点是比较好的。时间复杂度退化为最糟糕的 O(n2) 的情况,出现的可能性不大。
三.举例分析排序函数
一.JAVA排序算法流程图(JDK1.8)
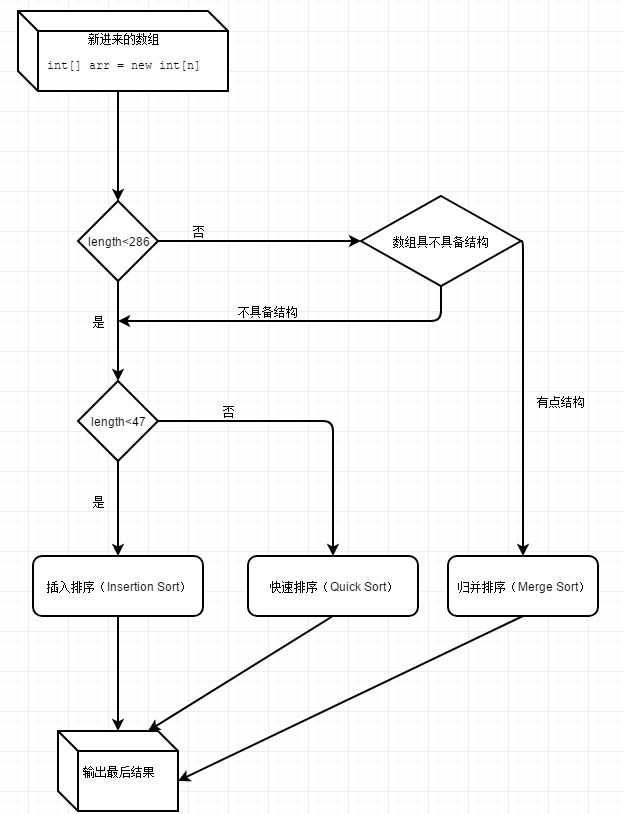
二.分析排序函数
java1.8中的排序,在元素小于47的时候用插入排序,大于47小于286用双轴快排,大于286用timsort归并排序,并在timesort中记录数据的连续的有序段的的位置,若有序段太多,也就是说数据近乎乱序,则用双轴快排,当然快排的递归调用的过程中,若排序的子数组数据数量小,用插入排序。
版权声明:本文不是「本站」原创文章,版权归原作者所有 | 原文地址: