二、Kafka 基础
在深入了解Kafka之前,您必须了解主题,经纪人,生产者和消费者等主要术语。 下图说明了主要术语,表格详细描述了图表组件。
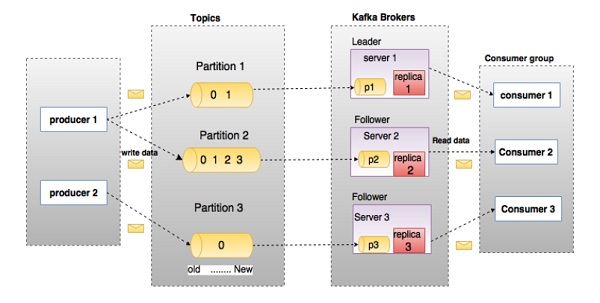
在上图中,主题配置为三个分区。 分区1具有两个偏移因子0和1.分区2具有四个偏移因子0,1,2和3.分区3具有一个偏移因子0.副本的id与承载它的服务器的id相同。
假设,如果主题的复制因子设置为3,那么Kafka将创建每个分区的3个相同的副本,并将它们放在集群中以使其可用于其所有操作。 为了平衡集群中的负载,每个代理都存储一个或多个这些分区。 多个生产者和消费者可以同时发布和检索消息。
| S.No | 组件和说明 |
|---|---|
| 1 | Topics(主题) 属于特定类别的消息流称为主题。 数据存储在主题中。 主题被拆分成分区。 对于每个主题,Kafka保存一个分区的数据。 每个这样的分区包含不可变有序序列的消息。 分区被实现为具有相等大小的一组分段文件。 |
| 2 | Partition(分区) 主题可能有许多分区,因此它可以处理任意数量的数据。 |
| 3 | Partition offset(分区偏移) 每个分区消息具有称为" offset "的唯一序列标识。 |
| 4 | Replicas of partition(分区备份) 副本只是一个分区的"备份"。 副本从不读取或写入数据。 它们用于防止数据丢失。 |
| 5 | Brokers(经纪人) - 代理是负责维护发布数据的简单系统。 每个代理中的每个主题可以具有零个或多个分区。 假设,如果在一个主题和N个代理中有N个分区,每个代理将有一个分区。 - 假设在一个主题中有N个分区并且多于N个代理(n + m),则第一个N代理将具有一个分区,并且下一个M代理将不具有用于该特定主题的任何分区。 - 假设在一个主题中有N个分区并且小于N个代理(n-m),每个代理将在它们之间具有一个或多个分区共享。 由于代理之间的负载分布不相等,不推荐使用此方案。 |