前言
在数据结构中,我们学习过 Java 的内置集合,但是我们知道,我们学过的大多数集合类都是线程不安全的,少数如 Vector,Stack,HashTable 是线程安全的,但这些都是一些比较“粗糙”的类(在所有方法上加了 synchronized 锁),一般不建议使用。
那么当我们想要在多线程下使用集合类该怎么处理呢?
一、多线程使用线性表
方式1:手动给会出现线程安全问题的逻辑加锁。
例如多个线程修改 ArrayList,此时可能出现问题,就可以给修改操作进行加锁。
方式2:使用 Collections.synchronizedList(); 封装
将想要使用的线性表用上述方法封装起来,相当于给集合里的关键方法加上了锁。
方式3:使用使用 CopyOnWriteArrayList
CopyOnWriteArrayList 原理
CopyOnWriteArrayList又称写时复制的容器。当我们往一个容器添加元素的时候,不直接往当前容器添加,而是先将当前容器进行Copy,复制出一个新的容器,然后新的容器里添加元素,添加完元素之后,再将原容器的引用指向新的容器。- 这样做的好处是我们可以对 CopyOnWriteArrayList 容器进行并发的读,而不需要加锁(只有在写时加锁),因为当前容器不会添加任何元素。
- 所以说 CopyOnWriteArrayList 容器采用的是一种读写分离的思想,读和写不同的容器。
优点:
- 适用于读多写少的场景下。在读多写少的场景下,性能很高,不需要加锁竞争.
缺点:
- 在修改时需要重新拷贝容器,占用内存较多。
- 新写的数据不能被第一时间读取到,即可能出现“脏读”问题。
二、多线程使用栈和队列
多线程使用栈和队列,我们可以直接使用 Java 标准库提供的阻塞队列,因为带有阻塞功能,这些集合在多线程下是线程安全的:
ArrayBlockingQueue基于数组实现的阻塞队列LinkedBlockingQueue基于链表实现的阻塞队列PriorityBlockingQueue基于堆实现的带优先级的阻塞队列TransferQueue最多只包含一个元素的阻塞队列
三、多线程下使用哈希表
哈希表也是我们经常会使用到的集合类,而标准库提供了 3 种哈希表,3 种哈希表之间的区别也是一个非常重要的知识点,下面就花点时间,对比一下 HashMap、HashTable、ConcurrentHashMap。
(1)HashMap
HashMap 不必多说,这就是一个在单线程下使用的哈希表,本身是不安全的。
(2)HashTable
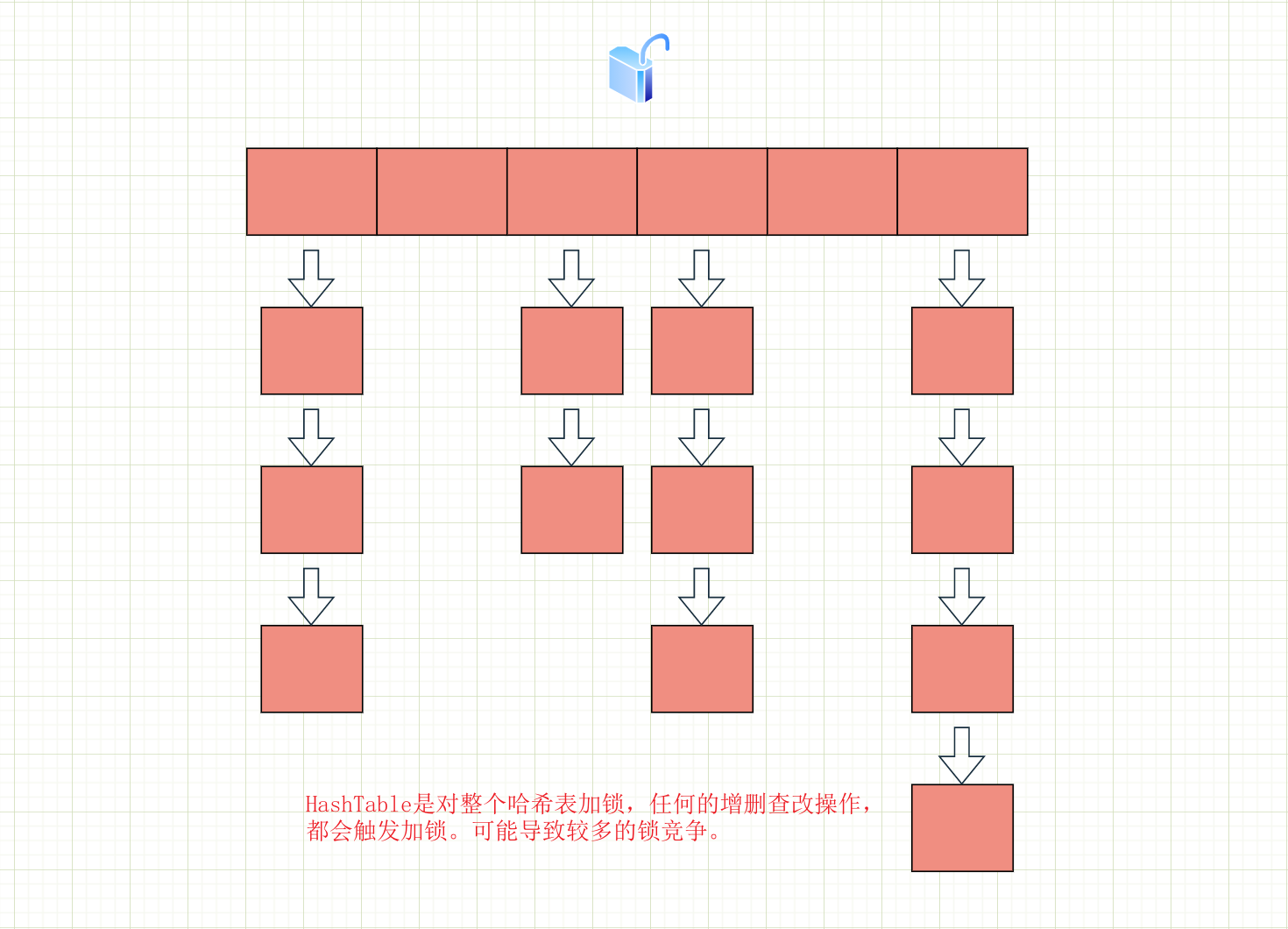
HashTable 是对其中的公共方法加上了 synchronized 锁,其实就想当于给整个哈希表上了锁。如果多个线程访问同一个 HashTable 就和产生锁竞争,而且一旦触发扩容就由该线程完成整个扩容过程,效率会非常低。我们可以简单画个图理解一下:
(3)ConcurrentHashMap
ConcurrentHashMap 在 HashTable 的基础上做了一些优化:
Java1.7 中主要的优化手段是:
使用的是分段锁技术, 简单的说就是把若干个哈希桶分成一个"段" (Segment),针对每个段分别加锁。目的也是为了降低锁竞争的概率。当两个线程访问的数据恰好在同一个段上的时候,才触发锁竞争。
Java1.8 中的优化
优化1:读写操作(最关键的优化)
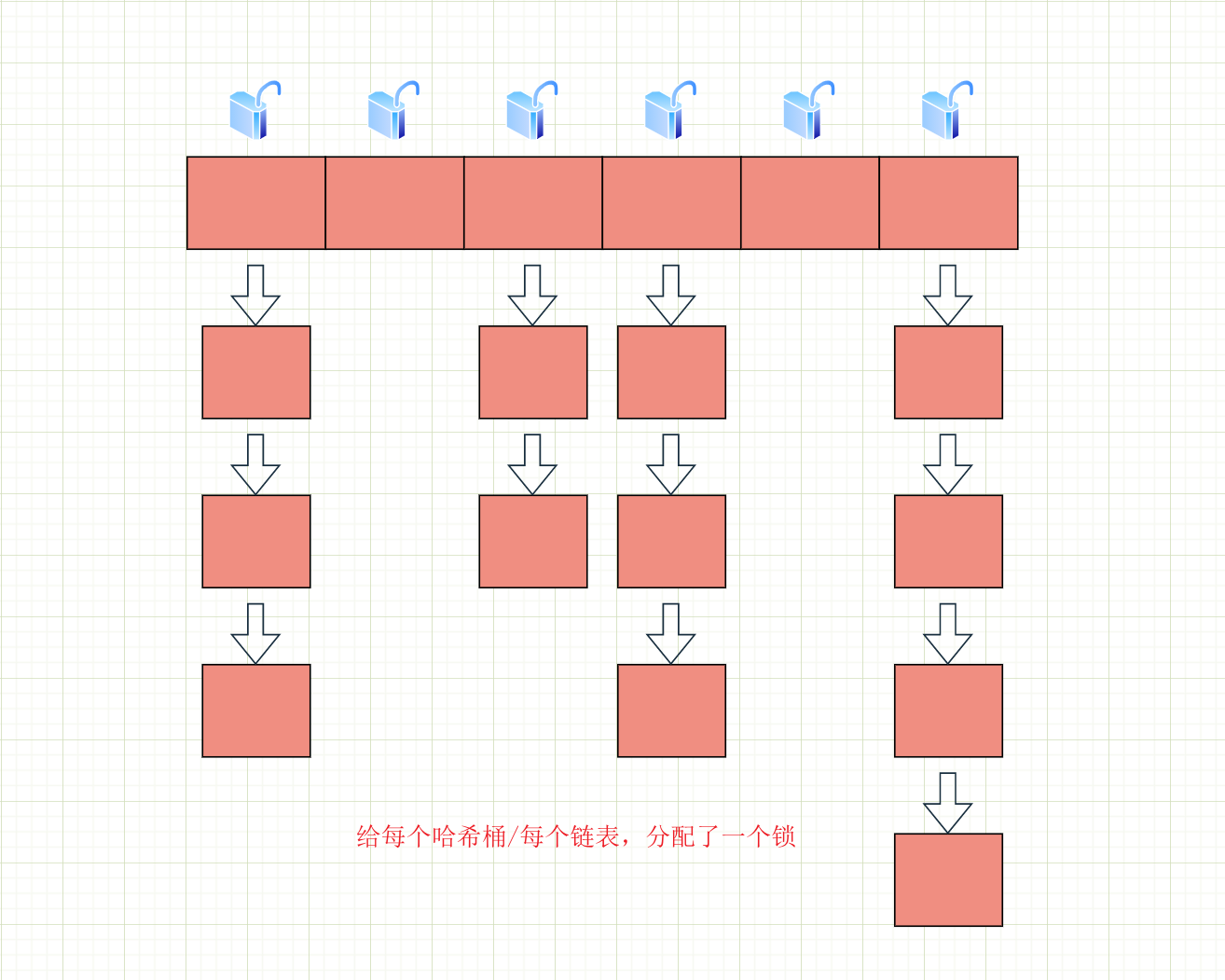
在Java1.8中取消了分段锁,直接给每个哈希桶/每个链表,分配了一个锁,就是以每个链表的头结点对象作为锁对象。在读操作上取消了加锁,使用了 volatile 保证从内存读取结果。同样我们画个图理解:
举个例子:
假如现在有两个线程,插入两个元素。线程 1 插入元素对应下标为 1 的链表上;线程 2 插入的元素,对应在下标为 2
的链表上。此时就相当于是两个线程修改不同的变量,显然是没有线程安全问题的。ConcurrentHashMap,每次插入操作只是针对对应的链表加锁,操作不同的链表就是针对不同的锁加锁,不会产生锁竞争。因此这就导致大部分加锁实际上是没有所冲突的,而这里的加锁操作开销也就微乎其微了。如果此时使用的是 HashTable,由于是对整个哈希表加锁,这两个插入依然会对同一个 this 产生锁竞争,产生阻塞等待。
优化2:重复利用CAS特性
例如更新、获取元素个数直接使用 CAS 完成,不必加锁。
优化3:优化扩容机制(化整为零)
我们知道哈希表中有一个参数叫做“负载因子”。如果元素过多,导致负载因子过大就要考虑扩容。
扩容就需要重新申请内存空间,把元素从旧的哈希表上删掉,插入到新的哈希表上。但是如果哈希表元素非常多,搬运一次就会导致这一次put操作非常卡顿。
而对于
ConcurrentHashMap的扩容策略——化整为零。发现需要扩容的线程,只需要创建一个新的数组(更大的内存空间),同时只搬几个元素过去。扩容期间,新老数组同时存在。后续每个来操作 ConcurrentHashMap 的线程,都会参与搬家的过程。每个操作负责搬运一小部分元素,搬完最后一个元素再把老数组删掉。在此期间,插入只往新数组加,查找需要同时查新数组和老数组。
优化4:底层实现
将原来数组 + 链表 的实现方式改进成 数组 + 链表 / 红黑树 的方式。当链表较长的时候(大于等于8 个元素)就转换成红黑树。
使用HashMap、HashTable、ConcurrentHashMap 冷知识:
- HashMap:key 允许为 null
- HashTable:key 不允许为 null
- ConcurrentHashMap:key 不允许为 null