一、锁的分类
Java中有着各种各样的锁,对于锁的分类也是多种多样,一把锁可能同时占有多个标准,符合多种分类。
对锁的常见分类有以下几个标准:
1. 偏向锁/轻量级锁/重量级锁
这三种锁特指 synchronized 锁的状态,JVM中通过在对象头中的 mark word 来表明锁的状态。这三个锁也刚好对应了JVM中对synchronized 锁升级的几个阶段:无锁→偏向锁→轻量级锁→重量级锁。
a. 偏向锁
如果自始至终,对于这把锁都不存在竞争,那么其实就没必要上锁,只需要打个标记就行了,这就是偏向锁的思想。
一个对象被初始化后,还没有任何线程来获取它的锁时,那么它就是可偏向的,当有第一个线程来访问它并尝试获取锁的时候,它就将这个线程记录下来,以后如果尝试获取锁的线程正是偏向锁的拥有者,就可以直接获得锁,开销很小,性能最好。
b. 轻量级锁
实际情况中,synchronized 中的代码是被多个线程交替执行的,而不是同时执行的,也就是说并不存在实际的竞争,或者是只有短时间的锁竞争,用 CAS 就可以解决,这种情况下,用完全互斥的重量级锁是没必要的。
轻量级锁是指当锁原来是偏向锁的时候,被另一个线程访问,说明存在竞争,那么偏向锁就会升级为轻量级锁,线程会通过自旋的形式尝试获取锁,而不会陷入阻塞。
c. 重量级锁
重量级锁是互斥锁,它是利用操作系统的同步机制实现的,所以开销相对比较大。当多个线程直接有实际竞争,且锁竞争时间长的时候,轻量级锁不能满足需求,锁就会膨胀为重量级锁。重量级锁会让其他申请却拿不到锁的线程进入阻塞状态。
从性能上来说,偏向锁性能最好,可以避免执行 CAS 操作。而轻量级锁利用自旋和 CAS 避免了重量级锁带来的线程阻塞和唤醒,性能中等。重量级锁则会把获取不到锁的线程阻塞,性能最差。
2. 可重入锁/非可重入锁
可重入锁指的是线程当前已经持有这把锁了,能在不释放这把锁的情况下,再次获取这把锁
不可重入锁指的是虽然线程当前持有了这把锁,但是如果想再次获取这把锁,也必须要先释放锁后才能再次尝试获取。
典型的可重入锁,就是ReentrantLock ,它是 Lock 接口最主要的一个实现类,reentrant 代表可重入。
3. 共享锁/独占锁
共享锁指的是我们同一把锁可以被多个线程同时获得,而独占锁指的就是,这把锁只能同时被一个线程获得。
最典型的案例就是读写锁,读写锁中的读锁,是共享锁,而写锁是独占锁。读锁可以被同时读,可以同时被多个线程持有,而写锁最多只能同时被一个线程持有。
4. 公平锁/非公平锁
公平锁的公平的含义在于如果线程现在拿不到这把锁,那么线程就都会进入等待,开始排队,在等待队列里等待时间长的线程会优先拿到这把锁,有先来先得的意思。
非公平锁就不那么“完美”了,它会在一定情况下,忽略掉已经在排队的线程,发生插队现象。注意,这里说的是在一定情况下(后续会介绍),非公平锁并不是任何时候都是非公平的。
5. 悲观锁/乐观锁
悲观锁的概念是在获取资源之前,必须先拿到锁,以便达到“独占”的状态,当前线程在操作资源的时候,其他线程由于不能拿到锁,所以其他线程不能来影响当前线程。
乐观锁恰恰相反,它并不要求在获取资源前拿到锁,也不会锁住资源;相反,乐观锁利用 CAS 理念,在不独占资源的情况下,完成了对资源的修改。
6. 自旋锁/非自旋锁
自旋锁的理念是如果线程现在拿不到锁,并不直接陷入阻塞或者释放 CPU 资源,而是开始利用循环,不停地尝试获取锁,这个循环过程被形象地比喻为“自旋”。
非自旋锁的理念就是没有自旋的过程,如果拿不到锁就直接放弃,或者进行其他的处理逻辑,例如去排队、陷入阻塞等。
7. 可中断锁/不可中断锁
不可中断锁是指一旦线程申请了锁,就没有回头路了,只能等到拿到锁以后才能进行其他的逻辑处理。典型的是synchronized关键字修饰的锁。
可中断锁是指当线程申请了锁,但后续又突然不想获取了,那么也可以在中断之后去做其他的事情,不需要一直傻等到获取到锁才离开。典型的是ReentrantLock。
二、悲观锁 VS 乐观锁
1. 悲观锁的思想
悲观锁的思想是,如果不锁住资源,别的线程就会来争抢,就会造成数据结果错误,所以悲观锁为了确保结果的正确性,会在每次获取并修改数据时,都把数据锁住,让其他线程无法访问该数据,这样就可以确保数据内容万无一失。
2. 乐观锁的思想
乐观锁的思想是,认为在操作资源的时候不会有其他线程来干扰,所以并不会锁住被操作对象,不会不让别的线程来接触它,同时,为了确保数据正确性,在更新之前,会去对比修改数据期间,数据有没有被其他线程修改过:如果没被修改过,就说明真的只有自己在操作,那就可以正常的修改数据;如果发现数据和一开始拿到的不一样了,说明其他线程在这段时间内修改过数据,就会放弃这次修改,并选择报错、重试等策略。乐观锁的实现一般都是利用 CAS 算法实现的。
3. 典型案例
悲观锁:synchronized 关键字和 Lock 接口
乐观锁:原子类
兼有两种锁:数据库。如果在 MySQL 选择 select for update 语句,那就是悲观锁,在提交之前不允许第三方来修改该数据;相反,可以利用一个版本 version 字段在数据库中实现乐观锁。在获取及修改数据时都不需要加锁,但是在获取完数据并计算完毕,准备更新数据时,会检查版本号和获取数据时的版本号是否一致,如果一致就直接更新,如果不一致,说明计算期间已经有其他线程修改过这个数据了,就可以选择重新获取数据,重新计算,然后再次尝试更新数据。
以下是SQL中实现乐观锁的示例
UPDATE student
SET
name = ‘小李’,
version= 2
WHERE id= 100
AND version= 1
4. 使用场景
直观来看,悲观锁由于操作比较重量级,不能多个线程并行执行,而且还会有上下文切换等动作,性能不及乐观锁,所以应该尽量避免用悲观锁。
其实这种想法有些过于片面。虽然悲观锁确实会让得不到锁的线程阻塞,但是这种开销是固定的。悲观锁的原始开销确实要高于乐观锁,但是特点是一劳永逸,就算一直拿不到锁,也不会对开销造成额外的影响。
相反,反观乐观锁虽然一开始的开销比悲观锁小,但是如果一直拿不到锁,或者并发量大,竞争激烈,导致不停重试,那么消耗的资源也会越来越多,甚至开销会超过悲观锁。
因此悲观锁和乐观锁没有谁更好这一说法,只是各有适用的使用场景
悲观锁适合用于并发写入多、临界区代码复杂、竞争激烈等场景,这种场景下悲观锁可以避免大量的无用的反复尝试等消耗。
乐观锁适用于大部分是读取,少部分是修改的场景,也适合虽然读写都很多,但是并发并不激烈的场景。在这些场景下,乐观锁不加锁的特点能让性能大幅提高。
三、公平锁 VS 非公平锁
公平锁指的是按照线程请求的顺序,来分配锁;而非公平锁指的是不完全按照请求的顺序,在一定情况下,可以允许插队。非公平锁并不是任何时候都允许插队的,仅仅在"合适的时机"允许插队。
1. 什么时候能"插队"?
那么什么是"合适的时机"呢?假设当前线程在请求获取锁的时候,恰巧前一个持有锁的线程释放了这把锁,那么当前申请锁的线程就可以不顾已经等待的线程而选择立刻插队。但是如果当前线程请求的时候,前一个线程并没有在那一时刻释放锁,那么当前线程还是一样会进入等待队列。
那为什么要在"合适的时机"插队呢?假设A 持有一把锁,线程 B 请求这把锁,由于线程 A 已经持有这把锁了,所以线程 B 会陷入等待,在等待的时候线程 B 会被挂起,也就是进入阻塞状态。当线程 A 释放锁的时候,本该轮到线程 B 苏醒获取锁,但如果此时突然有一个线程 C 插队请求这把锁,会把这把锁给线程 C。因为因为唤醒线程 B 是需要很大开销的,很有可能在唤醒之前,线程 C 已经拿到了这把锁并且执行完任务释放了这把锁。相比于等待唤醒线程 B 的漫长过程,插队的行为会让线程 C 本身跳过陷入阻塞的过程,如果在锁代码中执行的内容不多的话,线程 C 就可以很快完成任务,并且在线程 B 被完全唤醒之前,就把这个锁交出去,这样是一个双赢的局面,对于线程 C 而言,不需要等待提高了它的效率,而对于线程 B 而言,它获得锁的时间并没有推迟,因为等它被唤醒的时候,线程 C 早就释放锁了,因为线程 C 的执行速度相比于线程 B 的唤醒速度。
2. 公平锁和非公平锁的优缺点
| 优势 | 劣势 | |
|---|---|---|
| 公平锁 | 各线程公平,每个线程再等待一段时间后,总有执行的机会 | 更慢,吞吐量更小 |
| 非公平锁 | 更快,吞吐量大 | 有可能产生线程饥饿,即某些线程长时间内始终得不到执行 |
3. ReentrantLock 源码分析
典型的公平锁和非公平锁的实现是ReentrantLock,该类默认就是非公平锁,当初始化ReentrantLock式传入false时就是公平锁,传入true时就是非公平锁。
ReentrantLock 类包含一个 Sync 类,这个类继承自AQS(AbstractQueuedSynchronizer)
public class ReentrantLock implements Lock, java.io.Serializable {
private static final long serialVersionUID = 7373984872572414699L;
/** Synchronizer providing all implementation mechanics */
private final Sync sync;
Sync 类的代码:
abstract static class Sync extends AbstractQueuedSynchronizer {
...}
而Sync 有公平锁 FairSync 和非公平锁 NonfairSync两个子类:
static final class NonfairSync extends Sync {
...}
static final class FairSync extends Sync {
...}
公平锁获取锁的源码如下:
protected final boolean tryAcquire(int acquires) {
final Thread current = Thread.currentThread();
int c = getState();
if (c == 0) {
if (!hasQueuedPredecessors() && //这里判断了 hasQueuedPredecessors()
compareAndSetState(0, acquires)) {
setExclusiveOwnerThread(current);
return true;
}
} else if (current == getExclusiveOwnerThread()) {
int nextc = c + acquires;
if (nextc < 0) {
throw new Error("Maximum lock count exceeded");
}
setState(nextc);
return true;
}
return false;
}
非公平锁获取锁的源码如下:
final boolean nonfairTryAcquire(int acquires) {
final Thread current = Thread.currentThread();
int c = getState();
if (c == 0) {
if (compareAndSetState(0, acquires)) {
//这里没有判断hasQueuedPredecessors()
setExclusiveOwnerThread(current);
return true;
}
}
else if (current == getExclusiveOwnerThread()) {
int nextc = c + acquires;
if (nextc < 0) // overflow
throw new Error("Maximum lock count exceeded");
setState(nextc);
return true;
}
return false;
}
两者的区别在于,平锁在获取锁时多了一个限制条件:!hasQueuedPredecessors(),即判断在等待队列中是否已经有线程在排队了。一旦已经有线程在排队了,当前线程就不再尝试获取锁。
但是有一个方法比较特殊:tryLock() 方法,他并不遵循设定的公平原则。当有线程执行 tryLock() 方法的时候,一旦有线程释放了锁,即便是公平锁模式,这个正在 tryLock 的线程也能获取到锁。
查看tryLock()的源码:
public boolean tryLock() {
return sync.nonfairTryAcquire(1);
}
发现它调用的是nonfairTryAcquire(),表明了是不公平的,和锁本身是否是公平锁无关。
四、synchronized VS Lock
1. 两种方式的对比
共同点:
- 都是用来保护资源线程安全的
- 都可以保证可见性。对于 synchronized 而言,线程 A 在进入 synchronized 块之前或在 synchronized 块内进行操作,对于后续的获得同一个 monitor 锁的线程 B 是可见的;对于Lock 而言,在解锁之前的所有操作对加锁之后的所有操作都是可见的。
- synchronized 和 ReentrantLock 都可是可重入。
不同点:
-
用法区别:
-
synchronized 关键字可以加在方法上,不需要指定锁对象(此时的锁对象为 this),也可以新建一个同步代码块并且自定义 monitor 锁对象;
-
而 Lock 接口必须显示用 Lock 锁对象开始加锁 lock() 和解锁 unlock(),并且一般会在 finally 块中确保用 unlock() 来解锁,以防发生死锁。
-
与 Lock 显式的加锁和解锁不同的是 synchronized 的加解锁是隐式的,尤其是抛异常的时候也能保证释放锁
-
加解锁顺序不同:
-
对于 Lock 而言如果有多把 Lock 锁,Lock 可以不完全按照加锁的反序解锁,比如我们可以先获取 Lock1 锁,再获取 Lock2 锁,解锁时则先解锁 Lock1,再解锁 Lock2,加解锁有一定的灵活度
-
synchronized 解锁的顺序和加锁的顺序必须完全相反,因为 synchronized 加解锁是由 JVM 实现的,在执行完 synchronized 块后会自动解锁,所以会按照 synchronized 的嵌套顺序加解锁,不能自行控制。
-
synchronized 锁不够灵活:
-
一旦 synchronized 锁已经被某个线程获得了,此时其他线程如果还想获得,那它只能被阻塞,直到持有锁的线程运行完毕或者发生异常从而释放这个锁。如果持有锁的线程持有很长时间才释放,那么整个程序的运行效率就会降低,而且如果持有锁的线程永远不释放锁,那么尝试获取锁的线程只能永远等下去。
-
Lock 类在等锁的过程中,如果使用的是 lockInterruptibly 方法,那么如果觉得等待的时间太长了不想再继续等待,可以中断退出,也可以用 tryLock() 等方法尝试获取锁,如果获取不到锁也可以做别的事,更加灵活
-
原理区别:
-
synchronized 是内置锁,由 JVM 实现获取锁和释放锁的原理,还分为偏向锁、轻量级锁、重量级锁
-
Lock 根据实现不同,有不同的原理,例如 ReentrantLock 内部是通过 AQS 来获取和释放锁的
-
是否可以设置公平/非公平:
-
ReentrantLock 等 Lock 实现类可以根据自己的需要来设置公平或非公平,synchronized 则不能设置。
-
性能区别:
-
在 Java 5 以及之前,synchronized 的性能比较低
-
在 Java 6 以后,因为 JDK 对 synchronized 进行了很多优化,比如自适应自旋、锁消除、锁粗化、轻量级锁、偏向锁等,所以后期的 Java 版本里的 synchronized 的性能并不比 Lock 差。
2. synchronized 和 Lock如何选择?
- 能不用最好既不使用 Lock 也不使用 synchronized,在许多情况下可以使用 java.util.concurrent 包中的机制,它会处理所有的加锁和解锁操作,也就是推荐优先使用工具类来加解锁
- 如果某种场景下 synchronized 关键字更适合, 那么请尽量使用它,这样可以减少编写代码的数量,减少出错的概率。因为一旦忘记在 finally 里 unlock,代码可能会出很大的问题,而使用 synchronized 更安全
- 如果特别需要 Lock 的特殊功能,比如尝试获取锁、可中断、超时功能等,才使用 Lock
3. synchronized 的原理
synchronized 的背后是利用 monitor 锁实现的,每个 Java 对象都可以用作一个实现同步的锁,这个锁也被称为内置锁或 monitor 锁,获得 monitor 锁的唯一途径就是进入由这个锁保护的同步代码块或同步方法,线程在进入被 synchronized 保护的代码块之前,会自动获取锁,并且无论是正常路径退出,还是通过抛出异常退出,在退出的时候都会自动释放锁。
a. synchronized 同步代码块
如下所示:
public class SynTest {
public void synBlock() {
synchronized (this) {
System.out.println("lagou");
}
}
}
对SynTest 类进行操作,首先切换到SynTest 类的路径,执行 javac SynTest.java生成一个SynTest.class 的字节码文件,再执行 javap -verbose SynTest.class得到以下的反汇编:
public void synBlock();
descriptor: ()V
flags: ACC_PUBLIC
Code:
stack=2, locals=3, args_size=1
0: aload_0
1: dup
2: astore_1
3: monitorenter
4: getstatic #2 // Field java/lang/System.out:Ljava/io/PrintStream;
7: ldc #3 // String lagou
9: invokevirtual #4 // Method java/io/PrintStream.println:(Ljava/lang/String;)V
12: aload_1
13: monitorexit
14: goto 22
17: astore_2
18: aload_1
19: monitorexit
20: aload_2
21: athrow
22: return
synchronized 代码块实际上多了 monitorenter 和 monitorexit 指令,标红的第3、13、19行指令分别对应的是 monitorenter 和 monitorexit。这里有一个 monitorenter,却有两个 monitorexit 指令的原因是,JVM 要保证每个 monitorenter 必须有与之对应的 monitorexit,monitorenter 指令被插入到同步代码块的开始位置,而 monitorexit 需要插入到方法正常结束处和异常处两个地方,这样就可以保证抛异常的情况下也能释放锁
- monitorenter
可以理解为加锁,执行 monitorenter 的线程尝试获得 monitor 的所有权,会发生以下这三种情况之一:
a. 如果该 monitor 的计数为 0,则线程获得该 monitor 并将其计数设置为 1。然后,该线程就是这个 monitor 的所有者。
b. 如果线程已经拥有了这个 monitor ,则它将重新进入,并且累加计数。
c. 如果其他线程已经拥有了这个 monitor,那个这个线程就会被阻塞,直到这个 monitor 的计数变成为 0,代表这个 monitor 已经被释放了,于是当前这个线程就会再次尝试获取这个 monitor。 - monitorexit
可以理解为释放锁,作用是将 monitor 的计数器减 1,直到减为 0 为止。代表这个 monitor 已经被释放了,已经没有任何线程拥有它了,也就代表着解锁,所以,其他正在等待这个 monitor 的线程,此时便可以再次尝试获取这个 monitor 的所有权。
b. synchronized 同步方法
与同步代码块不同,synchronized 同步方法并不是依靠 monitorenter 和 monitorexit 指令实现的,而是依赖一个叫作 ACC_SYNCHRONIZED 的 flag 修饰符。
示例代码如下:
public synchronized void synMethod() {
}
反汇编之后的结果如下:
public synchronized void synMethod();
descriptor: ()V
flags: ACC_PUBLIC, ACC_SYNCHRONIZED
Code:
stack=0, locals=1, args_size=1
0: return
LineNumberTable:
line 16: 0
被synchronized 修饰的方法会有一个 ACC_SYNCHRONIZED 标志。当某个线程要访问某个方法的时候,会首先检查方法是否有 ACC_SYNCHRONIZED 标志,如果有则需要先获得 monitor 锁,然后才能开始执行方法,方法执行之后再释放 monitor 锁。其他方面, synchronized 方法和刚才的 synchronized 代码块是很类似的,例如这时如果其他线程来请求执行方法,也会因为无法获得 monitor 锁而被阻塞。
4. Lock的用法
Lock 接口中关注加解锁的方法有以下5个:
public interface Lock {
void lock();
void lockInterruptibly() throws InterruptedException;
boolean tryLock();
boolean tryLock(long time, TimeUnit unit) throws InterruptedException;
void unlock();
Condition newCondition();
}
a. lock() 方法
lock() 是最基础的获取锁的方法。在线程获取锁时如果锁已被其他线程获取,则进行等待,是最初级的获取锁的方法。
对于Lock 接口而言,获取锁和释放锁都是显式的,lock 的加锁和释放锁都必须以代码的形式写出来,所以使用 lock() 时必须主动去释放锁,因此最佳实践是执行 lock() 后,首先在 try{} 中操作同步资源,如果有必要就用 catch{} 块捕获异常,然后在 finally{} 中释放锁。
Lock lock = ...;
lock.lock();
try{
//获取到了被本锁保护的资源,处理任务
//捕获异常
}finally{
lock.unlock(); //释放锁
}
如果不遵守上述规范,就会让 Lock 变得非常危险,因为你不知道未来什么时候由于异常的发生,导致跳过了 unlock() 语句,使得这个锁永远不能被释放了,其他线程也无法再获得这个锁。
另外,lock() 方法不能被中断,这会带来很大的隐患:一旦陷入死锁,lock() 就会陷入永久等待。
b. tryLock() 方法
tryLock() 用来尝试获取锁,如果当前锁没有被其他线程占用,则获取成功,返回 true,否则返回 false,代表获取锁失败。
相比于lock()方法,tryLock() 方法功能更为强大,该方法会立即返回,即便在拿不到锁时也不会一直等待。该方法的典型使用如下:
Lock lock = ...;
if(lock.tryLock()) {
try{
//处理任务
}finally{
lock.unlock(); //释放锁
}
}else {
//如果不能获取锁,则做其他事情
}
tryLock() 方法可以帮助解决死锁问题,案例如下:
public void tryLock(Lock lock1, Lock lock2) throws InterruptedException {
while (true) {
if (lock1.tryLock()) {
try {
if (lock2.tryLock()) {
try {
System.out.println("获取到了两把锁,完成业务逻辑");
return;
} finally {
lock2.unlock();
}
}
} finally {
lock1.unlock();
}
} else {
Thread.sleep(new Random().nextInt(1000));
}
}
}
上述代码中,如果不使用tryLock,当有两个线程同时调用这个方法,传入的 lock1 和 lock2 恰好是相反的,那么如果第一个线程获取了 lock1 的同时,第二个线程获取了 lock2,它们接下来便会尝试获取对方持有的那把锁,但是又获取不到,于是便会陷入死锁。
有了tryLock() 方法之后,首先会检测 lock1 是否能获取到,如果能获取到再尝试获取 lock2,但如果 lock1 获取不到也没有关系,我们会在下面进行随机时间的等待,这个等待的目标是争取让其他的线程在这段时间完成它的任务,以便释放其他线程所持有的锁,以便后续供我们使用,同理如果获取到了 lock1 但没有获取到 lock2,那么也会释放掉 lock1,随即进行随机的等待,只有当它同时获取到 lock1 和 lock2 的时候,才会进入到里面执行业务逻辑,比如在这里我们会打印出“获取到了两把锁,完成业务逻辑”,然后方法便会返回。
c. tryLock(long time, TimeUnit unit) 方法
tryLock(long time, TimeUnit unit)是tryLock()的重载方法,它与tryLock()的区别在于tryLock(long time, TimeUnit unit) 方法会有一个超时时间,在拿不到锁时会等待一定的时间,如果在时间期限结束后,还获取不到锁,就会返回 false;如果一开始就获取锁或者等待期间内获取到锁,则返回 true。
该方法与tryLock()一样也可以帮助解决死锁问题。
d. lockInterruptibly() 方法
该方法同样是用于获取锁的,如果这个锁当前是可以获得的,那么这个方法会立刻返回,但是如果这个锁当前是不能获得的(被其他线程持有),那么当前线程便会开始等待,除非它等到了这把锁或者是在等待的过程中被中断了,否则这个线程便会一直在这里执行这行代码。一句话总结就是,除非当前线程在获取锁期间被中断,否则便会一直尝试获取直到获取到为止。
lockInterruptibly() 是可以响应中断的,可以把它理解为超时时间是无穷长的 tryLock(long time, TimeUnit unit),因为 tryLock(long time, TimeUnit unit) 和 lockInterruptibly() 都能响应中断,只不过 lockInterruptibly() 永远不会超时。
这个方法本身是会抛出 InterruptedException 的,使用的时候,如果不在方法签名声明抛出该异常,那么就要写两个 try 块。如下所示:
public void lockInterruptibly() {
try {
lock.lockInterruptibly();
try {
System.out.println("操作资源");
} finally {
lock.unlock();
}
} catch (InterruptedException e) {
e.printStackTrace();
}
}
e. unlock() 方法
该方法是用于解锁的,对于ReentrantLock 而言,由于是可重入锁,,执行 unlock() 的时候,内部会把锁的“被持有计数器”减 1,直到减到 0 就代表当前这把锁已经完全释放了,如果减 1 后计数器不为 0,说明这把锁之前被“重入”了,那么锁并没有真正释放,仅仅是减少了持有的次数。
五、读写锁ReadWriteLock
1. 读写锁的获取规则
- 当一个线程已经占有了读锁,那么其他线程如果想要申请读锁,可以申请成功;
- 当一个线程已经占有了读锁,而且有其他线程想要申请获取写锁的话,是不能申请成功的,因为读写互斥;
- 当一个线程已经占有了写锁,那么此时其他线程无论是想申请读锁还是写锁,都无法申请成功。
总结而言就是:读读共享,其他都互斥(写写、读写、写读)
2. ReentrantReadWriteLock
ReentrantReadWriteLock 是ReadWriteLock的实现类,分别有两个方法:readLock() 和 writeLock() 用来获取读锁和写锁
/**
* 描述: 演示读写锁用法
*/
public class ReadWriteLockDemo {
private static final ReentrantReadWriteLock reentrantReadWriteLock = new ReentrantReadWriteLock(
false);
private static final ReentrantReadWriteLock.ReadLock readLock = reentrantReadWriteLock
.readLock();
private static final ReentrantReadWriteLock.WriteLock writeLock = reentrantReadWriteLock
.writeLock();
private static void read() {
readLock.lock();
try {
System.out.println(Thread.currentThread().getName() + "得到读锁,正在读取");
Thread.sleep(500);
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
System.out.println(Thread.currentThread().getName() + "释放读锁");
readLock.unlock();
}
}
private static void write() {
writeLock.lock();
try {
System.out.println(Thread.currentThread().getName() + "得到写锁,正在写入");
Thread.sleep(500);
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
System.out.println(Thread.currentThread().getName() + "释放写锁");
writeLock.unlock();
}
}
public static void main(String[] args) throws InterruptedException {
new Thread(() -> read()).start();
new Thread(() -> read()).start();
new Thread(() -> write()).start();
new Thread(() -> write()).start();
}
}
运行结果如下:
Thread-0得到读锁,正在读取
Thread-1得到读锁,正在读取
Thread-0释放读锁
Thread-1释放读锁
Thread-2得到写锁,正在写入
Thread-2释放写锁
Thread-3得到写锁,正在写入
Thread-3释放写锁
相比于ReentrantLock 适用于一般场合,ReadWriteLock 适用于读多写少的情况,合理使用可以进一步提高并发效率。
3. 读写锁的插队策略
ReentrantReadWriteLock 和 ReentrantLock一样,都支持公平锁和非公平锁:
// 公平锁:
ReentrantReadWriteLock reentrantReadWriteLock = new ReentrantReadWriteLock(true);
// 非公平锁
ReentrantReadWriteLock reentrantReadWriteLock = new ReentrantReadWriteLock(false);
在获取读锁时,线程会检查readerShouldBlock() 方法。同样,在获取写锁之前,线程会检查 writerShouldBlock() 方法,来决定是否需要插队或者是去排队。
当ReentrantReadWriteLock 是公平锁时:
final boolean writerShouldBlock() {
return hasQueuedPredecessors();
}
final boolean readerShouldBlock() {
return hasQueuedPredecessors();
}
只要等待队列中有线程在等待,也就是hasQueuedPredecessors() 返回 true 的时候,那么 writer 和 reader 都会 block,也就是一律不允许插队。
当ReentrantReadWriteLock 是非公平锁时:
final boolean writerShouldBlock() {
return false; // writers can always barge
}
final boolean readerShouldBlock() {
return apparentlyFirstQueuedIsExclusive();
}
非公平锁时,对于想获取写锁的线程而言,由于返回值是 false,所以它是随时可以插队的,但是读锁却不一样,即便是非公平锁,只要等待队列的头结点是尝试获取写锁的线程,那么读锁依然是不能插队的。
那么为什么读锁不能像写锁一样,无脑支持插队呢?实际上不这样是为了防止线程"饥饿"。
假如有这样一个场景,线程 2 和线程 4 正在同时读取,线程 3 想要写入,但是由于线程 2 和线程 4 已经持有读锁了,所以线程 3 就进入等待队列进行等待。此时,如果不断有很多线程来执行读操作,允许插队的话,就会导致读锁长时间内不会被释放,线程3会长时间拿不到写锁,陷入"饥饿"状态。
以下是对读写锁的插队策略演示:
/**
* 描述: 演示读锁不插队
*/
public class ReadLockJumpQueue {
private static final ReentrantReadWriteLock reentrantReadWriteLock = new ReentrantReadWriteLock();
private static final ReentrantReadWriteLock.ReadLock readLock = reentrantReadWriteLock
.readLock();
private static final ReentrantReadWriteLock.WriteLock writeLock = reentrantReadWriteLock
.writeLock();
private static void read() {
readLock.lock();
try {
System.out.println(Thread.currentThread().getName() + "得到读锁,正在读取");
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
System.out.println(Thread.currentThread().getName() + "释放读锁");
readLock.unlock();
}
}
private static void write() {
writeLock.lock();
try {
System.out.println(Thread.currentThread().getName() + "得到写锁,正在写入");
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
System.out.println(Thread.currentThread().getName() + "释放写锁");
writeLock.unlock();
}
}
public static void main(String[] args) throws InterruptedException {
new Thread(() -> read(),"Thread-2").start();
new Thread(() -> read(),"Thread-4").start();
new Thread(() -> write(),"Thread-3").start();
new Thread(() -> read(),"Thread-5").start();
}
}
运行结果:
Thread-2得到读锁,正在读取
Thread-4得到读锁,正在读取
Thread-2释放读锁
Thread-4释放读锁
Thread-3得到写锁,正在写入
Thread-3释放写锁
Thread-5得到读锁,正在读取
Thread-5释放读锁
4. 读写锁的升降级
1. 降级
所谓降级,是指当前线程在不释放写锁的情况下直接获取读锁。
以下是对锁的降级演示:
public class CachedData {
Object data;
volatile boolean cacheValid;
final ReentrantReadWriteLock rwl = new ReentrantReadWriteLock();
void processCachedData() {
rwl.readLock().lock();
if (!cacheValid) {
//在获取写锁之前,必须首先释放读锁。
rwl.readLock().unlock();
rwl.writeLock().lock();
try {
//这里需要再次判断数据的有效性,因为在我们释放读锁和获取写锁的空隙之内,可能有其他线程修改了数据。
if (!cacheValid) {
data = new Object();
cacheValid = true;
}
//在不释放写锁的情况下,直接获取读锁,这就是读写锁的降级。
rwl.readLock().lock();
} finally {
//释放了写锁,但是依然持有读锁
rwl.writeLock().unlock();
}
}
try {
System.out.println(data);
} finally {
//释放读锁
rwl.readLock().unlock();
}
}
}
processCachedData()方法中:
- 先获取读锁,再判断缓存是否有效,有效则跳过整个if语句,不要更新缓存,在finally中释放读锁
- 如果缓存失效,需要更新缓存,此时需要获取写锁。首先释放读锁,再获取读锁,finally中再释放写锁。
- 在获取写锁后,判断缓存是否有效(可能有其他线程抢先更新了缓存),如果缓存无效,更新缓存。后续需要打印data,因此不能释放所有锁,此时选择降级,finally中在持有读锁的情况下释放读锁
那么为什么要用锁降级呢?可以一直使用写锁,最后再释放写锁呀?
答案是,可以一直使用写锁,但是没必要。因为使用写锁虽然可以保证线程安全,但代码中只有一处修改数据的地方:data = new Object(),后面对于data只是读取,一直采用写锁,就不能让多个线程同时来读取了,持有写锁是浪费资源的,降低了整体的效率。
2. 升级
所谓升级,是指当前在不释放读锁的情况下直接尝试获取写锁。ReentrantReadWriteLock 不支持升级,这会让程序直接阻塞,程序无法运行。
final static ReentrantReadWriteLock rwl = new ReentrantReadWriteLock();
public static void main(String[] args) {
upgrade();
}
public static void upgrade() {
rwl.readLock().lock();
System.out.println("获取到了读锁");
rwl.writeLock().lock();
// 不会打印出该结果,升级失败
System.out.println("成功升级");
}
那为什么不支持升级呢?
假如有A、B、C三个线程都已经持有读写锁,A想升级到写锁,根据读写锁的获取规则,就需要等待B和C都释放到所获取到的读锁。当B和C先后释放掉读锁后,A可以是哪里升级到写锁。
看起来是没什么问题。但是如果A和B都想升级到写锁呢?此时A和B都会需要等待对方释放读锁,导致死锁。
实际上,读写锁的升级是可行的,只需要保证每次只有一个线程可以升级,那么就可以保证线程安全。只是,ReentrantReadWriteLock 并不支持而已。
六、自旋锁
1. 自旋锁 vs非自旋锁
对于自旋锁,当获取锁失败时,线程并不会放弃CPU时间片,而是不断地再次尝试,直到成功为止。
对于非自旋锁,当获取锁失败时,会切换线程状态使线程休眠,释放时间片,CPU可以去做其他时间。而当锁释放后,CPU会将之前的线程恢复,线程再去尝试获取锁。如果失败,重复前面的步骤。
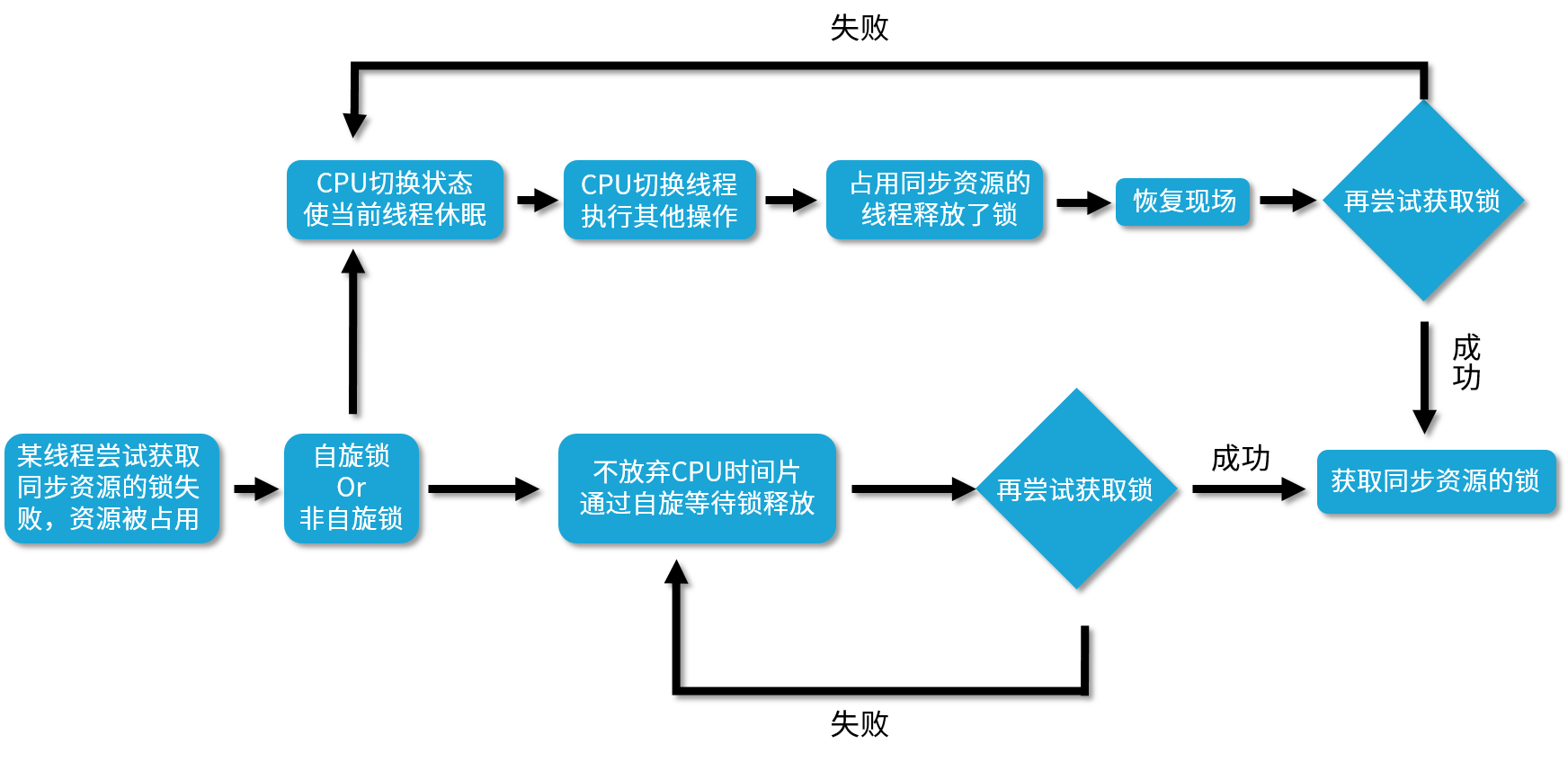
2. 自旋锁的优缺点
优点:
阻塞和唤醒线程都是需要高昂的开销的,如果同步代码块中的内容不复杂,执行时间也很短,那么可能转换线程带来的开销比实际业务代码执行的开销还要大。此时采用自旋锁,就可以避免上下文切换等开销,提高了效率
缺点:
虽然避免了线程切换,但是自旋锁自身不断获取锁的操作也是一种开销,虽然这种开销低于线程切换,但是获取的次数越多,等待的时间越久,累积的开销就会超过线程切换的开销。当锁一直不能被释放时,不断尝试的操作只会白白浪费处理器资源。
3. AtomicLong 内部的自旋锁实现
在Java 1.5 版本及以上的并发包中,也就是 java.util.concurrent 的包中,里面的原子类基本都是自旋锁的实现。
以AtomicLong 的getAndIncrement 为例:
public final long getAndIncrement() {
return unsafe.getAndAddLong(this, valueOffset, 1L);
}
其内部调用了调用了一个 unsafe.getAndAddLong方法
public final long getAndAddLong (Object var1,long var2, long var4){
long var6;
do {
var6 = this.getLongVolatile(var1, var2);
} while (!this.compareAndSwapLong(var1, var2, var6, var6 + var4));
return var6;
}
内部逻辑中,就是一个do-while的自旋操作,如果在修改过程中遇到了其他线程竞争导致没修改成功的情况,就会 while 循环里进行死循环,直到修改成功为止。
4. 自定义实现可重入的自旋锁
import java.util.concurrent.atomic.AtomicReference;
import java.util.concurrent.locks.Lock;
/**
* 描述: 实现一个可重入的自旋锁
*/
public class ReentrantSpinLock {
private AtomicReference<Thread> owner = new AtomicReference<>();
//重入次数
private int count = 0;
public void lock() {
Thread t = Thread.currentThread();
if (t == owner.get()) {
++count;
return;
}
//自旋获取锁
while (!owner.compareAndSet(null, t)) {
System.out.println("自旋了");
}
}
public void unlock() {
Thread t = Thread.currentThread();
//只有持有锁的线程才能解锁
if (t == owner.get()) {
if (count > 0) {
--count;
} else {
//此处无需CAS操作,因为没有竞争,因为只有线程持有者才能解锁
owner.set(null);
}
}
}
public static void main(String[] args) {
ReentrantSpinLock spinLock = new ReentrantSpinLock();
Runnable runnable = new Runnable() {
@Override
public void run() {
System.out.println(Thread.currentThread().getName() + "开始尝试获取自旋锁");
spinLock.lock();
try {
System.out.println(Thread.currentThread().getName() + "获取到了自旋锁");
Thread.sleep(4000);
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
spinLock.unlock();
System.out.println(Thread.currentThread().getName() + "释放了了自旋锁");
}
}
};
Thread thread1 = new Thread(runnable);
Thread thread2 = new Thread(runnable);
thread1.start();
thread2.start();
}
}
七、JVM对锁的优化
1. 自适应自旋锁
在上面提到AtomicLong 内部实现自旋锁的方式,是do-while循环,如果自旋时间过长,那么性能开销是很大的,浪费了 CPU 资源。
在JDK 1.6 中引入了自适应的自旋锁来解决长时间自旋的问题。自适应意味着根据最近自旋尝试的成功率、失败率,以及当前锁的拥有者的状态等多种因素来共同决定自旋时间。如果最近尝试自旋获取某一把锁成功了,那么下一次可能还会继续使用自旋,并且允许自旋更长的时间;但是如果最近自旋获取某一把锁失败了,那么可能会省略掉自旋的过程,以便减少无用的自旋,提高效率。
2. 锁消除
经过逃逸分析之后,如果发现某些对象不可能被其他线程访问到,那么就可以把它们当成栈上数据,栈上数据由于只有本线程可以访问,自然是线程安全的,也就无需加锁,所以会把这样的锁给自动去除掉。
典型的案例是StringBuffer 的 append 方法:
@Override
public synchronized StringBuffer append(Object obj) {
toStringCache = null;
super.append(String.valueOf(obj));
return this;
}
该方法被 synchronized 修饰的同步方法,因为它可能会被多个线程同时使用。但是,在大多数情况下,它只会在一个线程内被使用,如果编译器能确定这个 StringBuffer 对象只会在一个线程内被使用,就代表肯定是线程安全的,那么编译器便会做出优化,把对应的 synchronized 给消除,省去加锁和解锁的操作,以便增加整体的效率。
3. 锁粗化
public void lockCoarsening() {
synchronized (this) {
//do something
}
synchronized (this) {
//do something
}
synchronized (this) {
//do something
}
}
在代码中,存在多个代码块加锁再解锁,这样是没有必要的。可以把同步区域扩大,也就是只在最开始加一次锁,并且在最后直接解锁,那么就可以把中间这些无意义的解锁和加锁的过程消除,相当于是把几个 synchronized 块合并为一个较大的同步块。这样的话,在线程执行这些代码时,就无须频繁申请与释放锁了,这样就减少了性能开销。
但是,锁粗化不适用于循环的场景,仅适用于非循环的场景。
for (int i = 0; i< 1000; i++) {
synchronized (this) {
//do something
}
}
在第一次循环的开始,就开始扩大同步区域并持有锁,直到最后一次循环结束,才结束同步代码块释放锁的话,这就会导致其他线程长时间无法获得锁。
3. 锁升级
这是JDK对synchronized 锁的优化策略,synchronized 锁会经历:无锁 --> 偏向锁 --> 轻量级锁 --> 重量级锁的升级过程。具体各个锁的含义可以参考第一部分锁的分类。采用锁的升级,可以大幅提高锁的性能。