一、前言
磁盘在分区完成之后,要使得操作系统能够识别文件系统,就需要进行格式化,把分区格式化成某一个操作系统能够识别的文件系统。
一般来说,一个分区中装一个文件系统,但是现在技术发展了,一个分区可以装多个文件系统,也能将多个分区合并成一个文件系统。一个文件系统可以挂载到操作系统上。
二、EXT4文件系统
在Linux系统中,文件的权限与属性放到inode中,实际数据则放置到data block区块中。另外,还有一个超级区块superblock会记录整个文件系统的整体信息,包括inode与block使用量,剩余量等。
- inode:记录一个文件的所有属性,以及这个文件所对应的block的号码(一个文件对应一个inode)
- block:存放文件的实际数据(若文件数据太大,则使用多个block存放)
- super block:记录文件系统的整体信息,包括:inode、block的数量、文件系统的使用量、剩余量等。
在Linux系统中,为每个文件分配一个称为索引节点的号码inode,可以将inode简单理解成一个指针,它永远指向本文件的具体存储位置。
系统是通过索引节点(而不是文件名)来定位每一个文件。
三、EXT4文件系统读取数据的过程
系统先格式化出inode与block的区块。如下图,要访问一个文件时,首先找到这个文件的inode,根据inode中的权限查看当前用户是否有权力读取这个文件;然后根据inode中记录的block的号码,操作系统据此排列磁盘阅读顺序,一口气将四个block内容读出。最后找到block,读出数据。这种文件系统就叫做索引式文件系统。
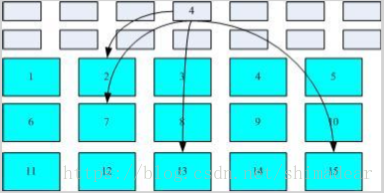
U盘(闪存)一般使用FAT文件系统,而FAT文件系统并没有inode,每个block中记录着本文件下一个block的位置。所以FAT文件系统无法通过inode一次性将这个文件所有的block号码读取出来,而只能一个个地读取block后才能知道下一个block的位置。如下图:
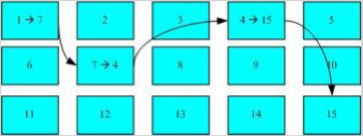
上图中我们假设文件的数据依序写入1->7->4->15号这四个 block 号码中, 但这个文件系统没有办法一口气就知道四个 block 的号码,他得要一个一个的将 block 读出后,才会知道下一个 block 在何处。如果同一个文件数据写入的 block 分散的太过厉害时,则我们的磁盘读取头将无法在磁盘转一圈就读到所有的数据, 因此磁盘就会多转好几圈能完整的读到到这个文件的内容。
所以如果同一个文件的block分散地太开,那么读取一个文件的时间就会很长,所以就有所谓的“碎片整理“,就是将同一个文件的block们尽量放到一起去。但Linux的EXT4文件系统由于是索引式的,因此不太需要碎片整理。
四、EXT4文件系统的一些补充说明
Linux之所以能支持多种文件系统,其实是由于Linux提供了一个虚拟文件系统VFS,VFS作为实际文件系统的上层软件,掩盖了实际文件系统底层的具体结构差异,为系统访问位于不同文件系统的文件提供了一个统一的接口。
1、 有些文件系统非常大,高达数百GB,那么格式化后会有大量的inode和block,为了方便管理,文件系统对所有的inode和block进行分组,每一组叫做blockgroup,每一组都有独立的inode/block/superblock;
2、 datablock数据块是用来存储文件实际数据的地方,只有1KB、2KB、4KB这三种;
3、 所有的inode和block在格式化的时候大小和数量就固定了,而且每一个block都有固定的编号,便于inode查找;
4、 文件系统支持的最大磁盘容量和单一文件容量是不一样的;
| block大小 | 1KB | 2KB | 4KB |
|---|---|---|---|
| 最大单一文件容量 | 16GB | 256GB | 2T |
一个block只能存放一个文件的数据,如果文件太大,则使用多个block存放,如果一个block放不满,则剩下的就空着。
1、 每个block的大小要合理地选择,如果太大,会造成最后一个block中会有大量剩余的空间;如果太小,那么inode中就要记录更多的block号码,每次找block要耗时,所以这样效率也不高;
2、 由于每个inode在格式化的时候大小就已经固定了,并且只有128bytes,并且每个文件仅能占用一个inode,因此,文件系统能够创建的文件数与inode的数量有关除此之外:;
3、 当一个文件很大时,它的block太多,每个block号码需要4byte,那么inode记录不下了怎么办?这时候将block号码存在一个block中,inode仅仅需要记录这个block的号码即可,这就是一次间接索引Linux的ext2文件系统最多支持3级间接索引;
4、 superblock记录了整个文件系统的相关信息,是非常重要的,如果superblock死掉了,那么系统会花费大量时间去挽救他;
5、 一般superblock的大小为1024bytes;
6、 每个blockgroup中都含有一个superblock,由于一个文件系统中只能有一个superblock,所以这些group中的superblock都是一样的,在第一个superblock挂了的时候进行挽救用的;
参考文章
1、 https://blog.csdn.net/shimadear/article/details/81035477;
版权声明:本文不是「本站」原创文章,版权归原作者所有 | 原文地址: